링크
문제 요약
$N$번의 시험에 대한 정보 ($i$번째 시험에서 $P_i$ 문제 중 $T_i$개를 맞음) 가 주어질 때, 성적은 $\displaystyle{ {\sum_{i=1}^{N}T_i}\over{\sum_{i=1}^{N}P_i} }$ 로 정의된다. 이때, 맞은 문제의 비율이 낮은 시험 $D$개를 제외할 때의 성적과 비교하여 더 나은 성적이 나올 수 있는 조합이 존재하는 모든 $D$ 값의 개수와 값을 출력하여라. (단, 모든 $i\ne{}j$에 대하여 $\displaystyle{ { {T_i}\over{P_i} } \ne{} { {T_j}\over{P_j} } }$ 이다.)
관찰
우선 맞은 문제의 비율이 낮은 시험 $D$개를 제외한 성적을 $S_D$ 라고 하자. 편의상 입력된 성적을 맞은 문제의 비율순으로 오름차순 정렬했다고 할 때, $\displaystyle S_D={ {\sum_{i=D+1}^{N}T_i}\over{\sum_{i=D+1}^{N}P_i} }$ 임을 알 수 있다. 이제 전체 $N$개의 시험중에서 $N-D$개의 시험을 뽑은 집합 $X$를 생각해보자. 우리가 구해야 할 집합은 $\displaystyle S_X={ {\sum_{i \in{} X} T_i}\over{\sum_{i \in{} X }P_i} } > S_D$ 를 만족하는 집합 $X$ 이다. 문제에서 구체적으로 최적의 값이 얼마인지를 묻지 않고, 그러한 집합 $X$의 존재성만 묻고 있기 때문에, 값을 구하기 보단 존재성을 밝히는데 집중하도록 하자.
위 식을 이항하여 정리해보면, $\displaystyle {\sum_{i \in{} X} {(T_i - P_i \times{} S_D)} } > 0$ 임을 쉽게 알 수 있다. 이때 시그마 안의 값의 형태를 생각해보면, $y=-{P_i}x+T_i$ 형태의 직선에 $x=S_D$ 일 때의 함수 값임을 알 수 있다. 따라서 아래 그림과 같이 각 $i$에 대하여 직선을 시각화해보자. 빨간색 직선은 $i=D+1, D+2, \cdots{}, N$ 일 때의 직선이고, 파란색 직선은 그 이외의 직선을 의미한다.
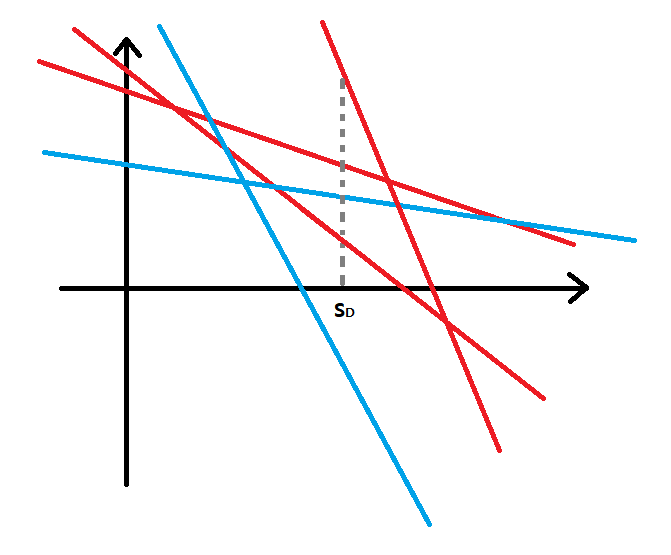 |
|---|
| Figure 1 |
예를 들어, 위 그림과 같이 $N=5, D=2$ 일 때를 생각해보자. $\displaystyle {\sum_{i \in{} X} {(T_i - P_i \times{} S_D)} }$ 값은 집합 $X=\lbrace{}3,4,5\rbrace{}$ 일 때, 다시 말해 조합이 $S_D$와 같을 때 $0$ 값을 갖게 된다. 주어진 식을 최대화하는 방법을 생각해보면, 자명히 함수의 값이 가장 큰 $N-D$개의 직선을 고르면 될 것이다. 이 때, 선정된 집합이 $\lbrace{}D+1,D+2,\cdots{},N\rbrace{}$ 과 다르다면 구하고자 하는 값은 $0$보다 항상 크게 된다.
그렇다면 선정된 집합이 $\lbrace{}D+1,D+2,\cdots{},N\rbrace{}$ 과 다른지 확인을 하는 것에 집중하자. 이 과정은 빨간색 직선들의 $x=S_D$ 함수값 중 최솟값과 파란색 직선들의 $x=S_D$ 함수값 중 최댓값을 각각 $R$ 과 $B$ 라고 할 때, $R<B$ 여부를 확인하면 된다. 만약 $R<B$ 라면, 우리가 찾고자하는 집합 $X$가 존재함을 알 수 있다. 위의 예시의 경우 $x=S_D$의 함수값이 가장 큰 3개의 직선에 파란색 직선이 존재하는 것을 볼 수 있고, 이는 맞은 문제의 비율이 낮은 2개를 버리는 것보다 더 나은 조합이 존재함을 의미한다.
풀이
이제 이를 빠르게 구하는 방법에 대하여 생각해보도록 하자. 관찰에서 볼 수 있듯이, 성적을 정렬한 후 해당 성적들을 직선으로 해석한 뒤 특정 지점에서의 최솟값과 최댓값을 알아야한다. 이 과정은 전형적인 Convex Hull Trick으로 구할 수 있는 상황이다. 하지만 문제점은 기울기의 경향성이 존재하지 않는다는 점이다. 기울기의 경향성이 존재하지 않는 경우에 대표적인 선택지는 Li-Chao Tree를 사용하는 것이다. 즉, 빨간색 직선들의 최솟값과 파란색 직선들의 최댓값을 Li-Chao Tree를 통해 구할 수 있고, 이 두가지 정보를 종합하여 문제를 해결할 수 있게된다.
이 글에서는 다른 방법을 소개하도록 한다. 대부분의 Convex Hull Trick 문제의 경우 직선의 기울기는 상수지만, 대개 y절편에 해당되는 값이 DP 값과 연관이 되어 있어 모든 직선에 대한 정보를 사전에 알기가 어렵다. 하지만 이 문제의 경우 직선에 대한 정보를 $y=-{P_i}x+T_i$ 로써 초기에 바로 알 수 있다. 따라서 각 노드가 구간에 대한 CHT 결과물을 담고 있는 Segment Tree를 구성하도록 하자. 그렇게 하면, 마치 merge sort tree를 construct 하듯이 두 노드의 결과를 합쳐서 $[s,e]$번째 직선들로 구성된 CHT를 구성해 나갈 수 있다. 이렇게 Segment Tree를 구성하고 나면 각 쿼리는 $O(\log{}^2N)$의 시간에 계산이 가능함을 쉽게 알 수 있다.
시간 복잡도를 정리하면 아래와 같다.
- 주어진 성적을 정렬 $O(N\log{}N)$
- 각 노드가 CHT인 Segment Tree를 Construct $O(N\log{}N)$
- 모든 $D$ 값에 대하여 $R<B$ 여부를 위에서 생성한 Segment Tree에 쿼리를 날리면 된다. 이 과정은 각 쿼리당 $O(\log{}^2N)$ 이므로 $O(N\log{}^2N)$
따라서 총 $O(N\log{}^2N)$ 의 시간에 문제가 해결된다. 아래는 구현에 사용된 코드이다.
1 | |