개요
이 포스팅에서는 트리 분할 기법인 Heavy Light Decomposition 과 그 구현에 대하여 다룬다.
이론
Heavy Light Decomposition은 트리의 간선들을 무거운 간선과 가벼운 간선으로 구분하여 분해하는 방식이다. 각각의 정의를 알아보면 다음과 같다.
정점 $x$ 를 루트로 하는 서브트리의 크기를 $size(x)$ 라고 정의하자.
트리에서 현재 정점을 $v$, $v$ 의 자식 노드들을 $u_i$ 라고 하자.
자명히 $v$ 와 $u_i$ 를 잇는 간선들이 존재할 것이고, $(v,u_i)$ 들에 대하여,
무거운 간선이란 $size(u_i)$ 가 최대인 $u_i$ 에 대하여, 간선 $(v,u_i)$ 를 의미한다.
가벼운 간선이란 무거운 간선을 제외한 나머지 간선을 의미한다.
예를 들어 아래와 같은 트리에서 무거운 간선은 빨간색 간선이 된다.
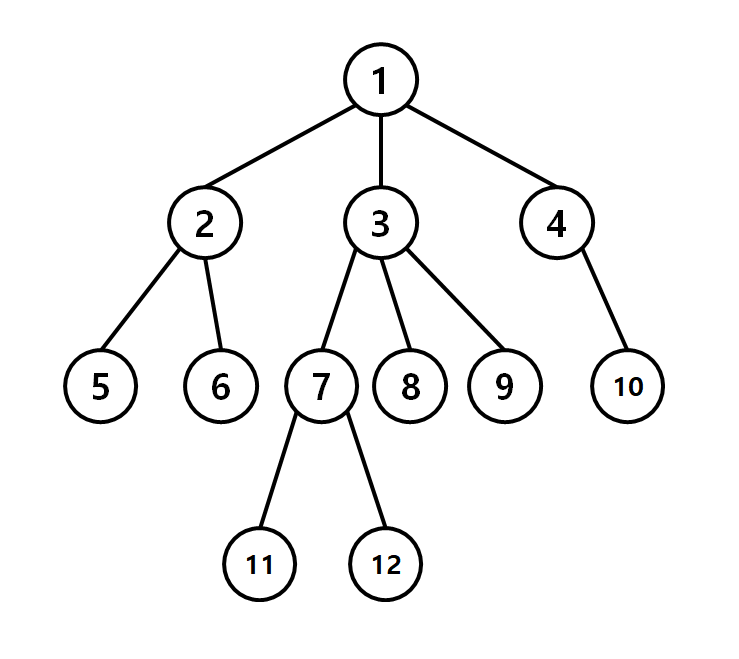 |
 |
|---|---|
| Figure 1 | Figure 2 |
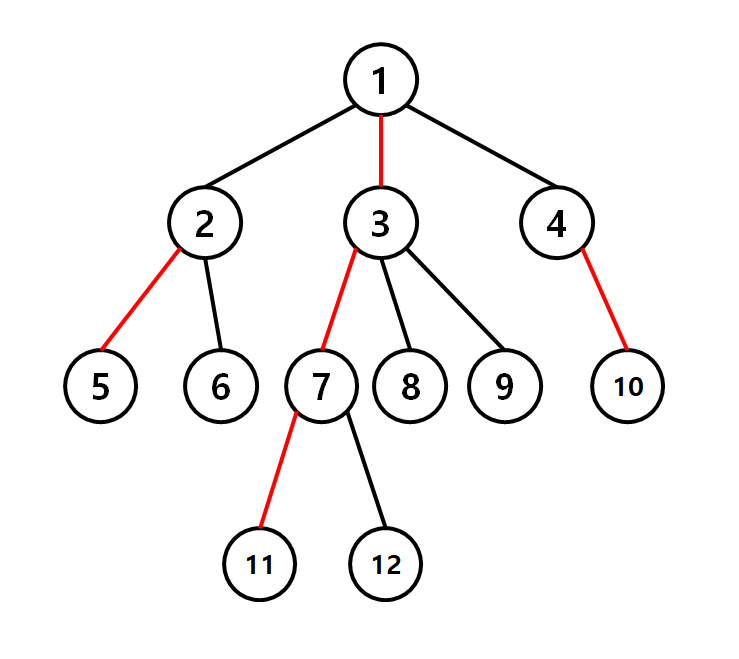
HLD란, 이러한 무거운 간선들을 계속 연결하여 트리를 여러개의 체인으로 분해하는 것을 의미한다. 만약 해당 간선이 무거운 간선이 아닌 경우, 그 자식노드를 새로운 체인의 시작점으로 하여 무거운 간선을 계속 연결하는 것을 반복하는 구조이다. 따라서 위의 트리를 HLD 한 결과물은 아래와 같이 된다.
 |
|---|
| Figure 3 |
이렇게 하면 대체 무슨 효과가 있길래 분해를 한 것일까? 이렇게 트리를 HLD 하게 되면, 임의의 두 정점 $u$ 에서 $v$ 로 가는 단순 경로상에 체인이 최대 $O(\log{N})$ 개 존재하게 된다.
Proof )
현재 자신이 속한 체인의 시작점을 $x$ 라고 하고, $x$ 와 sibling 관계이면서 이번에 바뀌게 될 체인에 속한 정점을 $x’$ 라고하자.
그러면 무거운 간선의 정의에 의해, $size(x)\leq{size(x’)}$ 가 성립한다.
따라서 체인을 갈아탈 때마다 서브트리의 크기가 2배 이상 커지게 되므로, 체인이 변경되는 횟수는 $\log{N}$ 번을 넘을 수 없다.
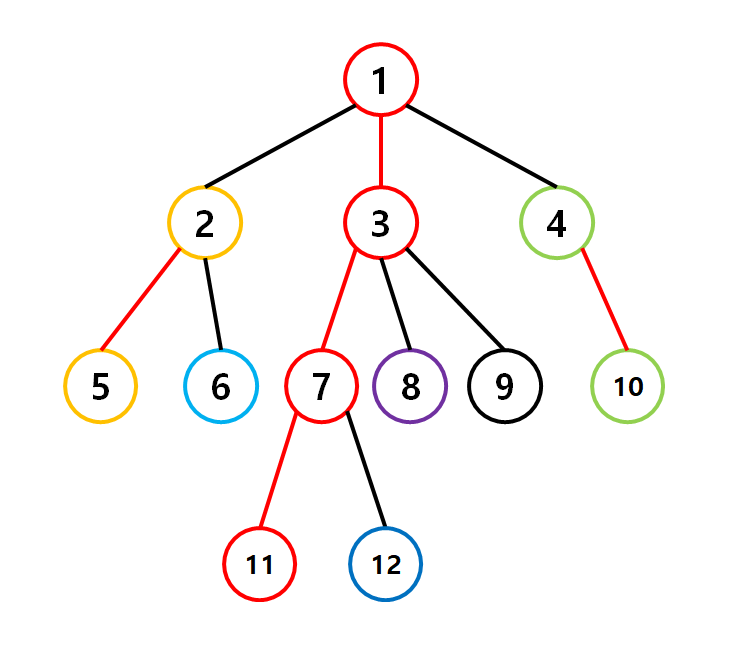
실제로 예를들어 10번에서 12번으로 이동하는 동안 체인은 총 2번 바뀌고, 체인의 시작점이 루트에 더 가까운 체인으로 갈아탈 때마다 서브트리의 크기는 2배 이상 커짐을 확인 할 수 있다. (10번에서 1번 정점으로 넘어갈 때, 12번에서 7번으로 넘어갈 때를 잘 보자.)
그러므로 임의의 두 정점 $u$ 에서 $v$ 로 가는 단순 경로상에 체인이 최대 $O(\log{N})$ 개 존재한다는 사실을 활용하여 다양한 작업을 효율적으로 할 수 있을 것이다. 이 사실을 어떻게 활용하는지 알아보도록 하자.
HLD의 활용
LCA 구하기
rooted tree에서 임의의 두 정점간에는 LCA라고 하는 정점이 반드시 존재하게 된다. 이러한 LCA를 찾는 방법은 Sparse Table을 이용하여 $O(\log{N})$ 에 구할 수 있음이 널리 알려져 있다. 하지만 HLD를 이용해서도 LCA를 $O(\log{N})$ 에 구할 수 있다. 이는 상당히 명확한데, 앞서 예를 든 상황에서 체인을 갈아탈 때는 자신보다 더 depth 가 얕은 방향으로 간다(=루트 방향으로 올라간다.)는 것을 보면, 이 과정을 두 정점이 같은 체인에 속할 때 까지 반복하면 두 정점 중 1개가 LCA 위치에 있다는 것을 알 수 있다.
이해를 위해 실제로 앞서 말한 10번 정점과 12번 정점에서 출발하여 서로 같은 체인에 존재할 때까지 정점을 이동시켜보도록 하자. 10번 정점이 1번으로 가고, 12번 정점이 7번에 도착하면 서로 같은 체인에 존재하게 되고, 둘의 LCA는 1번 정점이다.
경로상의 쿼리 해결
BOJ 13510 트리와 쿼리 1
위의 문제를 해결하는데 HLD를 사용할 수가 있다. 앞서 언급한 바와 같이 임의의 경로상의 체인은 $O(\log{N})$ 개 존재하기 때문에, LCA로 올라가면서 각 체인별로 문제를 해결하면, $O(\log{N}\times{T(a)})$ 에 쿼리를 처리할 수 있다. (이때 $T(a)$ 는 길이가 $a$ 인 체인에서 최댓값을 찾는데 걸리는 시간)
해당 문제의 경우 세그먼트 트리를 각 체인별로 사용하면 될 것이고, $O(\log^2{N})$ 에 쿼리를 처리할 수 있을 것이다. 즉, HLD를 사용하면 트리를 여러개의 직선(=체인)으로 분해한 뒤 각각을 풀어냄으로써, 더 쉬운 문제를 푸는 상황으로 치환할 수 있는 의의가 있다.
구현
구현은 생각보다 간단하다. 앞서 이론에서 설명한 내용을 그대로 구현하면 된다. 총 2번의 DFS를 해서 HLD를 구현할 수 있고, 첫번째 DFS는 각 서브트리의 사이즈를 계산하고, 두번째 DFS는 실질적으로 각 정점이 어떤 체인에 속하는지를 계산한다. 먼저 코드를 살펴보도록 하자.
1 | |
각 부분을 분석해보면 다음과 같다. dfs 함수가 앞서 말한 첫번째 DFS이고, HLD 함수가 두번째 DFS 이다. HLD를 할 때, 최소한으로 저장해야 할 데이터는 (서브트리의 크기, 노드의 depth, 노드의 parent, 각각 자신이 속한 체인의 시작정점) 이다. 이는 변수로 (sz, dep, par, top) 에 대응된다. 아직 설명하지 않은 변수는 뒤에서 그 이유를 말하겠다.
dfs 함수를 분석하는 것은 상당히 간단하다. 굉장히 간단한 트리 DP로 서브트리 크기를 계산할 수 있고, 각 정점의 depth 와 parent를 찾는 과정은 해당 함수를 보면 자명하다.
다음으로 HLD 함수를 보자. HLD 함수는 일단 첫줄에 dfsn을 저장한다. dfsn 이란 트리에서 HLD 함수를 통해 순회를 할 때, 몇 번째로 자신이 방문되었는지를 기록한다. 이것이 어떻게 활용되는지는 나중에 설명하도록 한다. 그 이후 28~31 번째 줄은 가장 서브트리 크기가 큰 정점을 찾는 과정이다. 즉, 무거운 간선을 찾는 과정이다.
만약 현재 노드가 리프노드라면, 더 이상 무거운 간선이 존재하지 않고, 따라서 바로 return 한다. 이후 무거운 간선으로 먼저 이동하여 HLD 를 수행하고, 이 과정에서 top[v]=top[cur] 를 사용하면 현재의 체인을 이어가는 효과가 된다. 그 이후 34~38 번째 줄은 가벼운 간선에 대하여 처리를 하는 것이고, 가벼운 간선에 해당하는 정점은 새로운 체인의 시작점이므로, top[nxt]=nxt로 저장한다.
실제로 트리를 분해하는 것은 이렇게 2개의 함수가 끝이다. 하지만 HLD를 활용하는 것이 우리의 목적이므로, 가장 기본이 되는 LCA를 구하는 과정 역시 구현을 해놓아야 한다. LCA를 구하는 과정은 다음과 같다. 만약 현재 두 정점 u와 v가 같은 체인에 없다면, 같은 체인에 속할 때까지 정점을 이동시켜야 한다. 이때 어떤 정점을 이동시킬 것인지는 각 정점 u와 v에 대하여 둘중에 자신이 속한 체인의 시작점의 depth가 더 깊은 정점을 이동시키야 한다. 그 과정이 LCA 함수의 while 문이고, while 문이 끝나면 두 점은 반드시 같은 체인에 존재한다. 따라서 둘중에 depth가 더 얕은 정점이 LCA가 됨은 자명하다.
마지막으로 여기서 사용되지 않은 dfsn을 기록한 이유를 설명하겠다. dfsn을 기록한 이유는 각 체인별로 세그먼트 트리를 이용하여 구간 쿼리 문제를 해결하는데 사용하기 위해서이다. 이론에서는 각 체인별 세그먼트 트리를 구축한다고 했지만, 실제로는 하나의 세그먼트 트리에 적절한 위치로 update를 함으로써 해결이 가능하다.
세그먼트 트리에 값을 update할 때 원소의 인덱스를 dfsn 값으로 구성하면, 같은 체인에 속한 정점들끼리는 dfsn 값이 연속적이게 된다. 따라서 현재 정점(=cur) 에서 체인의 시작점까지의 구간에 대한 답을 얻고 싶으면, qry(dfsn[top[cur]],dfsn[cur]) 를 부르면 된다. 이해를 돕기위해 예시 코드를 하나 첨부하도록 하겠다.
예시 코드 : BOJ 13512 트리와 쿼리 3
정리
지금까지 내용을 정리하면, HLD란 트리를 적절하게 여러개의 직선들로 분해하여 문제를 해결하게 된다. 트리를 HLD 한 이후에는 위에 주어진 코드를 기반으로 적절한 자료구조를 추가하여 약간의 변형을 하면 대부분의 문제가 풀릴 것이다. 특히 LCA 함수가 대부분의 쿼리 문제에서는 qry 함수가 될 것이고 이는 앞서 올려놓은 예시 코드를 보면 알 수 있다.